Building a model
from pathlib import Path
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
from patsy import dmatrix
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.nonparametric.smoothers_lowess import lowessBuilding a model¶
In this section we will look at pratical example of how we can build a regression model to see how whether membrane resistance, spike threshold and resting membrane potential contribute to rheobase. Often we just want to test whether our measure is different between genotype, treatment, sex, etc. However, we can actually build a more biological plausible model that also gets into some simple causal analysis. This analysis will also cover several techniques such as model comparison, residual analysis and intepretation of regression coefficients. One thing to note is that rheobase is specifically excludes the effects of capacitance since we measure it with an infinitely long current injection. Additionally, this dataset seems to have bimodal capacitance which will throw off the whole regression equation so we are leaving out of the model but showing the data here. Another benefit of building a model with this dataset is that it will touch on some core regression modeling methodology, namely non-linear relationships and some mediation analysis.
Setting the baseline¶
First we are going to see how well predicted rheobase matches up to the actual rheobase. We can use the simple equation for the relationship between resistance and rheobase. To get we will subtract the resting membrane potential from the spike threshold. To get we will divide by . We will regress the predicted rheobase against the actual rheobase using a simple linear regression. Then we will analyze the regression output.
Load and prepare the data¶
The dataset being used for this chapter is the same data used for the MSN data in other chapters. I and others recorded D1-tdTom+ and D1-tdTom- cells from adult mice (~P90). A couple notes on how the data was analyzed. Membrane resistance was measured using the currents injections from -150 to 150 and is the slope coefficient of the regression current ~ delta_v. A slow current was injected to keep the cells close to -70 mV. The spike threshold was measured using the peak of the third derivative. Capacitance (Cm) was measured on break-in using a test pulse. To prepare our dataset we will need to rename our columns so we can use the statsmodels formula API. This means we need to remove spaces, parenthesis, brackets, etc. for the column names.
data_path = Path().cwd().parent / "data/stats/msn_data.csv"
df = pd.read_csv(data_path)
df = df.dropna(subset="Vm_B", axis="rows")
df["deltav_mem"] = df["Spike threshold (mV)"] - df["Vm_B"]
df["synth_rheo"] = (df["deltav_mem"] / df["Membrane resistance"]) * 1000
df["mem_res"] = df["Membrane resistance"]
df["inv_mem_res"] = 1/df["mem_res"]
df["rheo"] = df["Rheobase (pA)"]
df["log_rheo"] = np.log(df["Rheobase (pA)"])
df["log_mem"] = np.log(df["mem_res"])
df["spk_thresh"] = df["Spike threshold (mV)"]
df["log_deltav_mem"] = np.log(df["deltav_mem"])Run the regression¶
model_fit = smf.ols("rheo ~ synth_rheo", data=df).fit()Plot the resulting fit and the points.
fig, ax = plt.subplots()
ax.plot(df["synth_rheo"], df["Rheobase (pA)"], ".")
x = np.linspace(df["synth_rheo"].min(), df["synth_rheo"].max(), num=100)
fit = model_fit.params["Intercept"] + model_fit.params["synth_rheo"]*x
ax.plot(x, fit)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)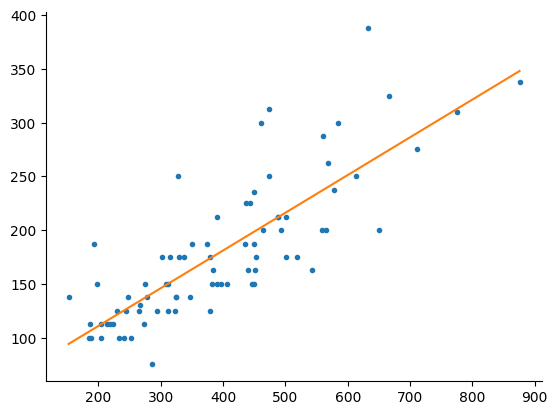
The fit looks goods, but how good is it? Notice how the predicted rheobase seems about 2x larger than the actual rheobase. We can look at the actual model to get more information about this relationship.
Analyze the regression¶
print(model_fit.summary()) OLS Regression Results
==============================================================================
Dep. Variable: rheo R-squared: 0.658
Model: OLS Adj. R-squared: 0.654
Method: Least Squares F-statistic: 150.3
Date: Tue, 02 Jun 2026 Prob (F-statistic): 7.16e-20
Time: 20:48:42 Log-Likelihood: -403.89
No. Observations: 80 AIC: 811.8
Df Residuals: 78 BIC: 816.5
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 40.6580 12.036 3.378 0.001 16.697 64.619
synth_rheo 0.3509 0.029 12.258 0.000 0.294 0.408
==============================================================================
Omnibus: 16.904 Durbin-Watson: 1.840
Prob(Omnibus): 0.000 Jarque-Bera (JB): 20.587
Skew: 1.014 Prob(JB): 3.39e-05
Kurtosis: 4.436 Cond. No. 1.19e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.19e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
Some things to note about the model summary. Our slope coefficent, synth_rheo is 0.3509 which means if we compare one cell with a rheobase of say 100 and one with a rheobase of 101 the difference in actual rheobase between the two cells would be 0.3509. This means our input needs to be multiplied by 0.3509 to get to the actual rheobase. This is pretty close to the estimate of the predicted rheobase being 2x larger than the actual rheobase. Why is the slope not close to one? It might depend on how we measure membrane resistance. For this data set the cell was held at -70 mV by injecting a slow (DC) current. I regressed the delta v against the current injection amplitude only for acquisition with 150 pA of the 0 pA current injection. We have different sets of ion channels that are active at current injections. Ih channels open below -40 mV, Na+ channels start to open with depolarizing current injections, K+ leak channels are probably more important around the resting membrane potential just to name a few. What if we break down the predicted rheobase into its components? Lastly we should look at the confidence intervals to get an idea of how good our estimate is. Even though p < 0.05 this does not mean our estimate is precise it just means the confidence intrevals do not contain zero. A rule of thumb is if you are running and OLS or some variant such as weighted or robust regression, you do not log transform your outcome variable and your confidence intervals do not contain zero the take the ratio of the intervals where the absolute value of the larger interval is on top: abs(large)/abs(small). A rule of thumb is if this interval is > 3 then we have a weak effect. If you have log transformed your outcome then you need to exponentiate your coefficient and confidence intervals first. The exponentiated confiden. So for regression 0.408/0.294=1.388. So we can say that we are fairly confident in our slope measurement regardless of the p-value. If your confidence intervals contain zero then you need to decide on something called a region of pratical equivalence using two one-sided tests (TOST). Or you can decide on an effect size that is practical. Lastly we can look at Adj. R-squared to see how much variance is explained by our model. Adj. R-squared is like R-squared except that it is adjusted for sample size and number of coefficients. Adj. R-squared and R-squared actually converge when the estimated relationship is strong or you have a large sample size. One problem with Adj. R-squared is it is supposed to show us how variance is explained by our model but, it can be negative. This does not really matter because a R-squared close to zero means we explain vary little about the outcome variable with our model. Adj. R-squared at 0.654 is pretty good. That means 64% of our outcome is explained by our predictors. Later we will compare the Adj. R-squared of different models to get a sense of how big 0.654 really is.
Begining to breakdown the model¶
First let’s look at how the different components may be related.
columns = [
"rheo",
"mem_res",
"spk_thresh",
"Vm_B",
"Cm",
"deltav_mem"
]
fig, ax = plt.subplots(
nrows=len(columns), ncols=len(columns), layout="constrained", figsize=(15, 15)
)
values = len(columns)
for i in range(values):
for j in range(values):
if i != j:
x = df[columns[i]]
y = df[columns[j]]
model_fit = smf.ols(f"{columns[j]} ~ {columns[i]}", data=df).fit()
x_fit = np.linspace(df[columns[i]].min(), df[columns[i]].max(), num=100)
y_fit = model_fit.params["Intercept"] + model_fit.params[columns[i]]*x_fit
ax[i][j].plot(x, y, ".")
ax[i][j].set_xlabel(columns[i])
ax[i][j].set_ylabel(columns[j])
ax[i][j].plot(x_fit,y_fit)
else:
ax[i][j].hist(df[columns[i]], bins=15)
ax[i][j].set_xlabel(columns[j])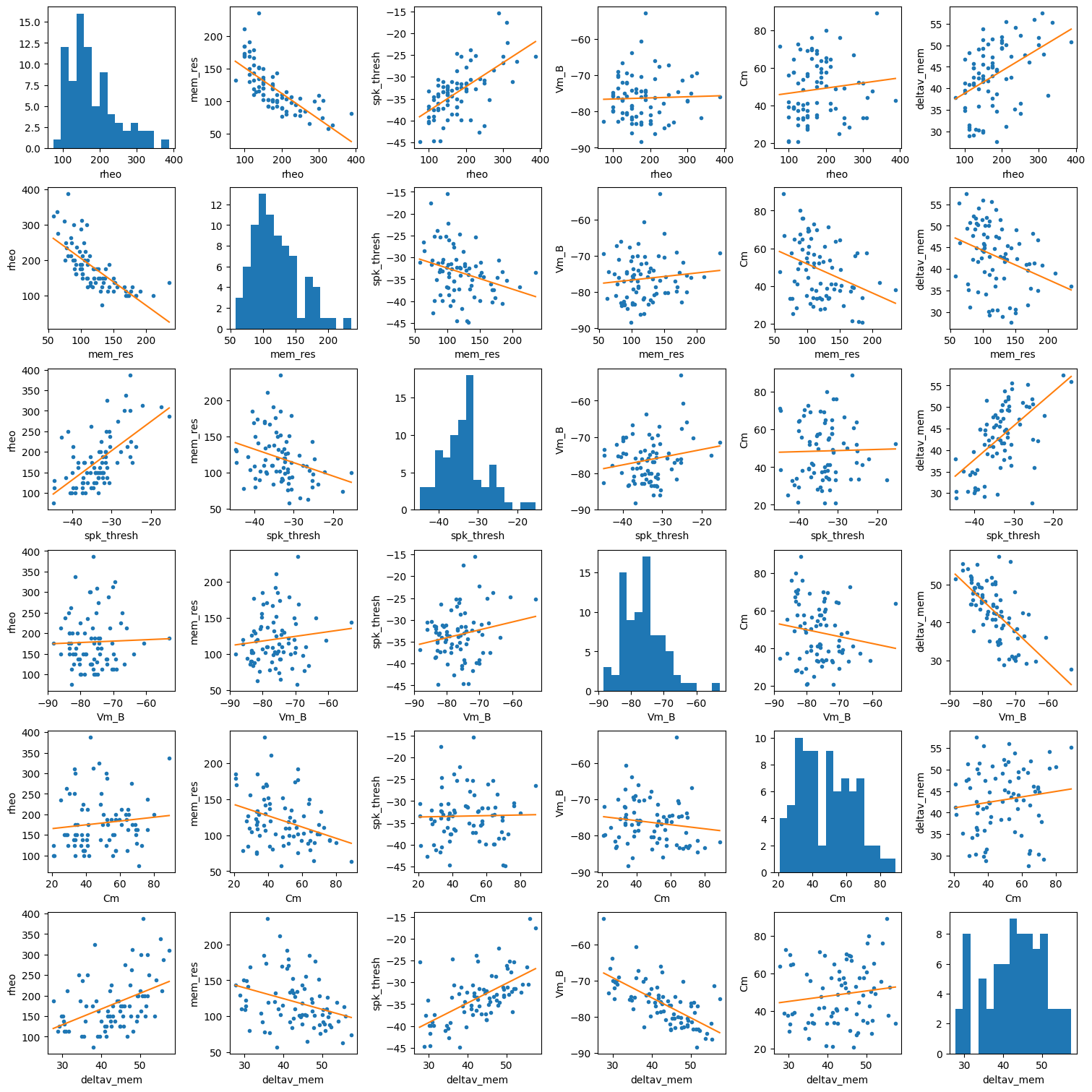
Probably the two biggest things that stand out are that membrane resistance and spike threshold seem to have some relationship with rheobase. The relationship between rheobase and membrane resistance is nonlinear. This makes sense since rheobase and membrane resistance are inversely proportional. Spike threshold is also negatively correlated with membrane resistance where as resting membrane potential is positively correlated. While there seem to be some linear relations between other variables the variance around the simple regression line is quite a lot. When we build a regression model with more predictors we want to avoid collinear features since this will impair the regression fit. Also if we look at the histogram distributions we can see that most variables are left skewed (tail to the right). This could be because of how we measure the membrane resistance. Since I injected a slow current to keep the cells as -70 mV this could change the types of ion channels that are being sampled.
Breaking down predicted rheobase¶
We know that to our predicted rheobase comes from the equation . This equation is nonlinear so to make is linear we can use a log transform . Now we have an equation where we can find the relative contribution of and . However, we cannot easily decompose . To decompose that we know that and are going to explain 100% of the variance in so we can just measure the variance by getting the joint variance . For we can ignore and since they will be 1. You can test this by running a regression delta_v ~ vm + vt and your coefficients will be 1 and -1 since 100% of the variance is explained. Then we can get the contributions for and with the following equations
and
vm_var = np.var(df["Vm_B"], ddof=1)
vt_var = np.var(df["Spike threshold (mV)"], ddof=1)
cov = np.cov(df["Spike threshold (mV)"], df["Vm_B"], ddof=1)[0, 1]
var_deltaV = np.var(df["deltav_mem"], ddof=1)
var_deltaV_calc = vt_var + vm_var - 2*cov
contrib_Vt = (vt_var - cov) / var_deltaV
contrib_Vm = (vm_var - cov) / var_deltaV
print(contrib_Vm, contrib_Vt)0.550823230967843 0.449176769032157
So we have about equal contribution of and to the variance of . Next let us see how much and predict rheobase.
model_fit = smf.ols("np.log(rheo) ~ np.log(deltav_mem) + np.log(mem_res)", data=df).fit()
print(model_fit.summary()) OLS Regression Results
==============================================================================
Dep. Variable: np.log(rheo) R-squared: 0.682
Model: OLS Adj. R-squared: 0.674
Method: Least Squares F-statistic: 82.56
Date: Tue, 02 Jun 2026 Prob (F-statistic): 6.99e-20
Time: 20:48:47 Log-Likelihood: 18.001
No. Observations: 80 AIC: -30.00
Df Residuals: 77 BIC: -22.86
Df Model: 2
Covariance Type: nonrobust
======================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------------
Intercept 7.9371 0.691 11.490 0.000 6.562 9.313
np.log(deltav_mem) 0.3760 0.126 2.994 0.004 0.126 0.626
np.log(mem_res) -0.8885 0.081 -11.008 0.000 -1.049 -0.728
==============================================================================
Omnibus: 6.539 Durbin-Watson: 2.069
Prob(Omnibus): 0.038 Jarque-Bera (JB): 8.018
Skew: 0.343 Prob(JB): 0.0182
Kurtosis: 4.391 Cond. No. 195.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
With this model we can see that most of rheobase is predicted by membrane resistance and less by delta V. Next we can run some simple models where we see how the coefficient changes.
model_fit = smf.ols("np.log(rheo) ~ np.log(mem_res)", data=df).fit()
print(model_fit.summary()) OLS Regression Results
==============================================================================
Dep. Variable: np.log(rheo) R-squared: 0.645
Model: OLS Adj. R-squared: 0.640
Method: Least Squares F-statistic: 141.7
Date: Tue, 02 Jun 2026 Prob (F-statistic): 3.22e-19
Time: 20:48:47 Log-Likelihood: 13.596
No. Observations: 80 AIC: -23.19
Df Residuals: 78 BIC: -18.43
Df Model: 1
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 9.6909 0.384 25.219 0.000 8.926 10.456
np.log(mem_res) -0.9615 0.081 -11.903 0.000 -1.122 -0.801
==============================================================================
Omnibus: 4.801 Durbin-Watson: 2.221
Prob(Omnibus): 0.091 Jarque-Bera (JB): 5.243
Skew: 0.252 Prob(JB): 0.0727
Kurtosis: 4.149 Cond. No. 82.6
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
model_fit = smf.ols("np.log(rheo) ~ np.log(deltav_mem)", data=df).fit()
print(model_fit.summary()) OLS Regression Results
==============================================================================
Dep. Variable: np.log(rheo) R-squared: 0.181
Model: OLS Adj. R-squared: 0.171
Method: Least Squares F-statistic: 17.29
Date: Tue, 02 Jun 2026 Prob (F-statistic): 8.15e-05
Time: 20:48:47 Log-Likelihood: -19.814
No. Observations: 80 AIC: 43.63
Df Residuals: 78 BIC: 48.39
Df Model: 1
Covariance Type: nonrobust
======================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------------
Intercept 2.1548 0.715 3.013 0.003 0.731 3.578
np.log(deltav_mem) 0.7936 0.191 4.159 0.000 0.414 1.174
==============================================================================
Omnibus: 1.057 Durbin-Watson: 1.906
Prob(Omnibus): 0.589 Jarque-Bera (JB): 1.129
Skew: 0.205 Prob(JB): 0.569
Kurtosis: 2.587 Cond. No. 81.8
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
We see that for both membrane resistance and delta V we get larger coefficients. This suggests that there is some correlation between those two variables. We can check that.
print(np.corrcoef(np.log(df['mem_res']), np.log(df['deltav_mem']))[0,1])-0.3020811532007374
df.columnsIndex(['D1_D2', 'Vm_B', 'Spike threshold (mV)', 'Membrane resistance',
'Rheobase (pA)', 'Cm', 'Rs_B', 'Rs_A', 'deltav_mem', 'synth_rheo',
'mem_res', 'inv_mem_res', 'rheo', 'log_rheo', 'log_mem', 'spk_thresh',
'log_deltav_mem'],
dtype='str')There is some correlation but a not a lot. Why can’t we perfectly predict rheobase with delta V and membrane resistance? There are several factors. One is likely due to how we measure membrane resistance using small current injections near the resting membrane potential. Both those variables are capturing the same information. Additionally, resting membrane potential is likely a noisy parameter. So when combined with the spike threshold to calculate delta V we get a less precise parameter. We can also see that the adjusted R2 is much higher for the membrane resistance model than the delta V model. We find that membrane resistance is a primary factor in rheobase. Delta V is probably a minor factor because membrane voltage dynamics are nonlinear.